

とっちゃん@nyanco! です。
今回はXPathについて書き方の基本を勉強したので分かりやすく解説するよというお話です。
そもそもXPathとは?
XPath(エックスパス)とはXML Path Languageの略で、XMLで書かれた文書の特定の部分を指定する構文のこと。
参考:wikipedia
スクレイピング系のRPA(Octoparseなど)で抽出したい箇所を特定する際などに使うようですが、今回はSelenium IDEのコマンド【store xpath count】で使いたいと思ったのが調べるきっかけでした。
XMLなんて分からないよ〜という方、筆者も同じくXMLについてはほぼ無知でしたが、基本的なレベルであればすぐに理解できたので大丈夫かと。
XML用なのにHTMLでも使えるのか?とも思いましたが、実際に問題なく使えました。
CSSセレクタとかなり似通っている部分があるので、その知識がある人は飲み込みが早いと思います。
【基礎】XPathの書き方
基本1:htmlタグ を / で区切る
下記のように htmlタグ を /(半角スラッシュ)で区切ってタグの階層順に記述するのが基本的な書き方となります。
/html/body/div

divタグなんてページにたくさんあるけど、そのうちのどれかを指定したい場合はどうするのかにゃ?
確かに通常のwebページには divタグ はたくさん存在しますよね。
上記だと該当する全ての divタグ が取得されてしまいます。
基本2:htmlタグ の何番目かを指定できる
下記のように書くと、複数あるタグの何番目かを指定することができます。
/html/body/div[2]

これで2番目の divタグ が指定できるということですかにゃ!
ズバリその通りで、タグ名の後に [n] と書くとn番目のタグを指定することになります。
基本3:途中までのパスは省略できる

でも、奥深いところにあるタグを指定するとドえらく長いパスになってしまわないですかにゃ?
これもその通りで、複雑なページだと下記のように非常に分かりづらいパスになります。
/html/body/div[2]/div/div/div/div/div/div/div/div/img
これを見やすく簡潔にするために、「//」で途中までのパスを以下のように省略することもできます。
//div/img

めちゃめちゃスッキリ見やすくなった!
…でもこれだとimgタグが複数あると特定しずらいですにゃ〜
ごもっともですね ^^;
ということで、次により詳しく指定できる方法をご紹介します。
基本4:属性で指定する
ここが基本の中で一番キモになります。
以下の形式で、タグの属性(id、class、style、href、titleなど)で指定することができます。
タグ名[@属性名=”属性値”]
具体的に書くと、
div[@class=”content”]
となります。
ちなみに基本2 の何番目指定と組み合わせることもでき、
div[@class=”content”][2]
上記の例だと “content” という class名 のついた 2番目 の divタグ という指定となります。
これでかなり特定できますにゃ!
これを最初に教えて欲しかったですにゃ〜
基本5:テキストで指定する
下記形式でタグ内のテキスト内容での指定もできます。
タグ名[text()=”テキスト内容”]
ただこちら、部分一致ではだめで、ズバリな内容で指定しないと取得できません。
【基礎】XPathの練習
以上の基本を踏まえ、下記のような簡単なページでXPathの練習を兼ねた実践をしてみます。
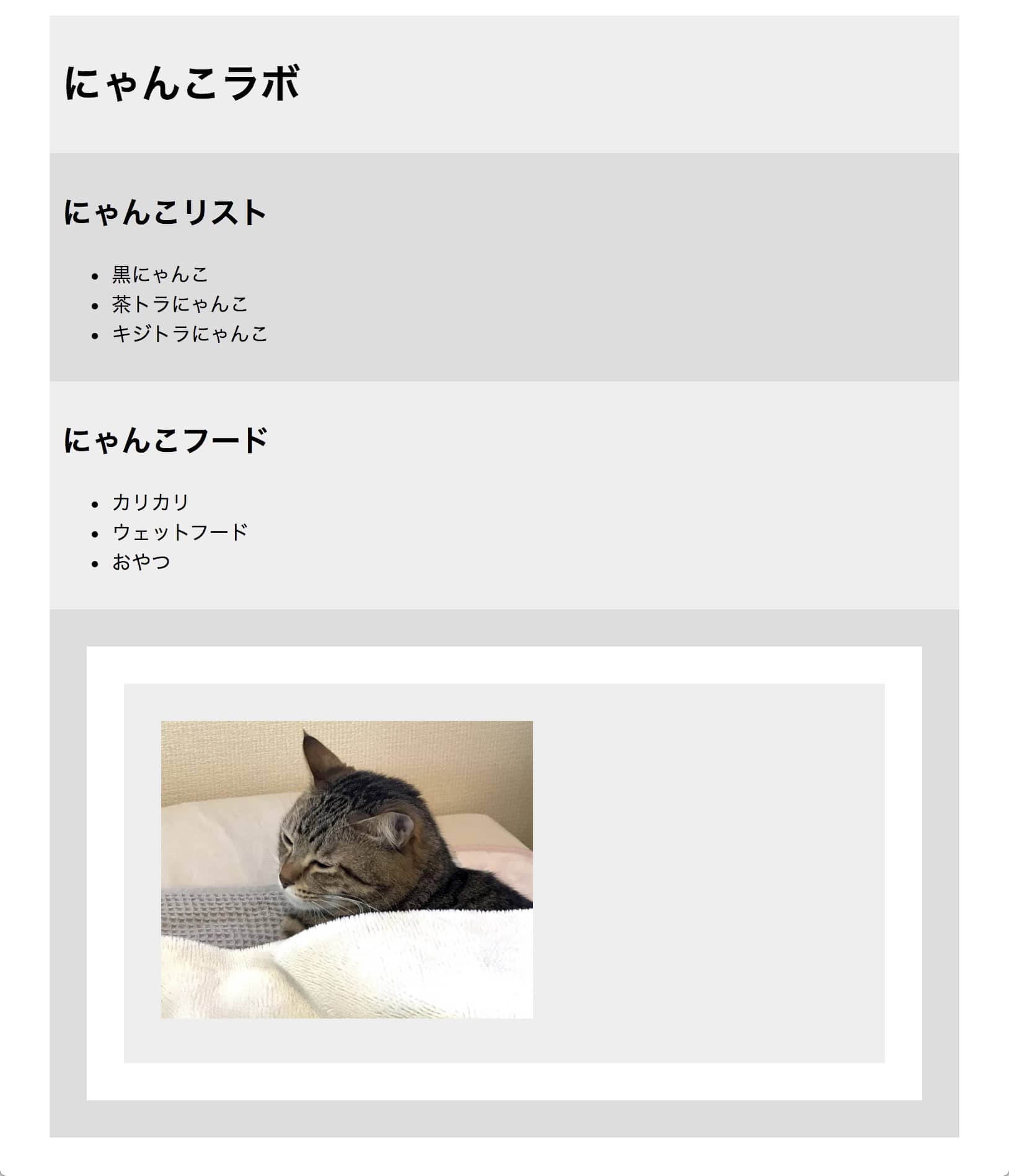
htmlタグを視覚化すると、▼以下のようになります。
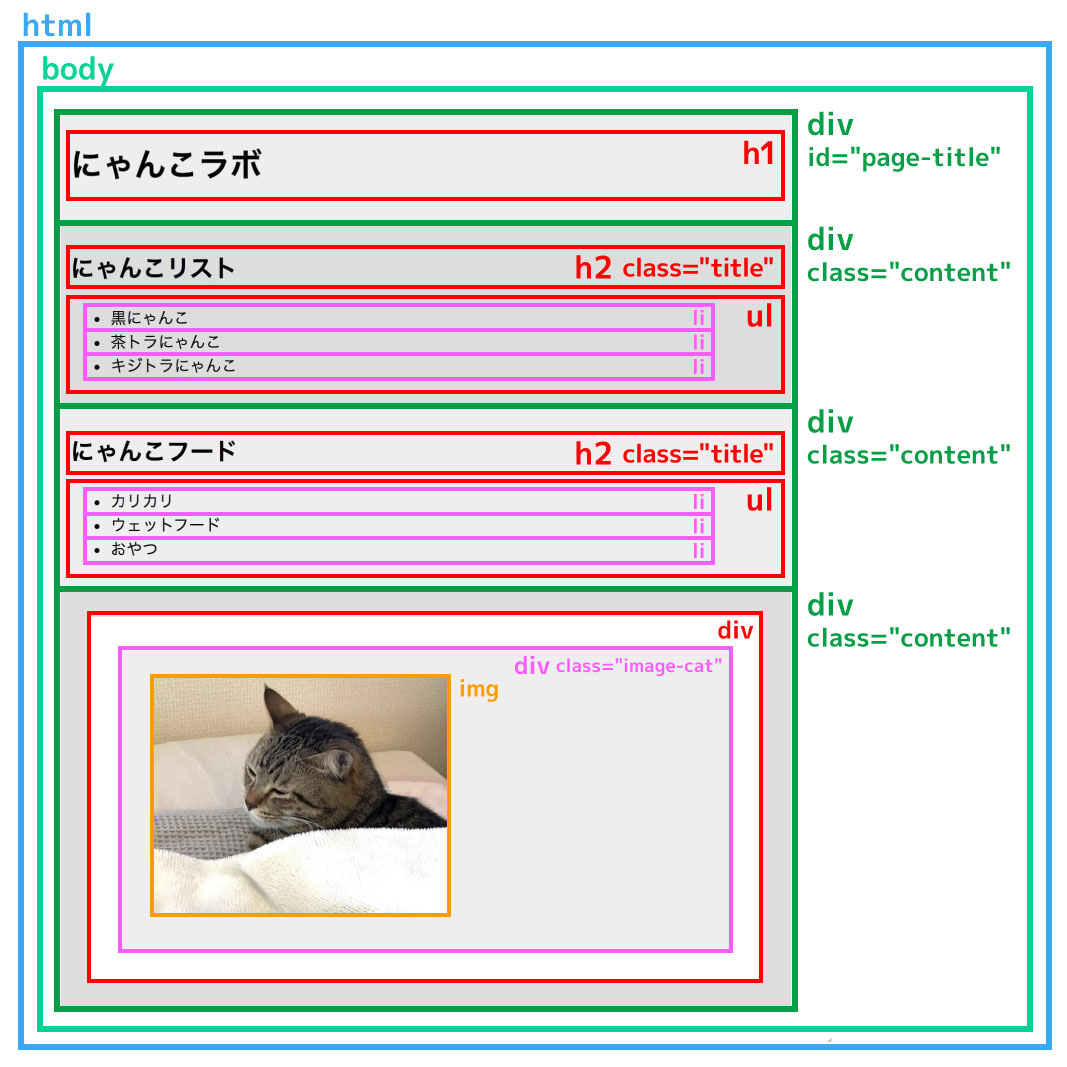
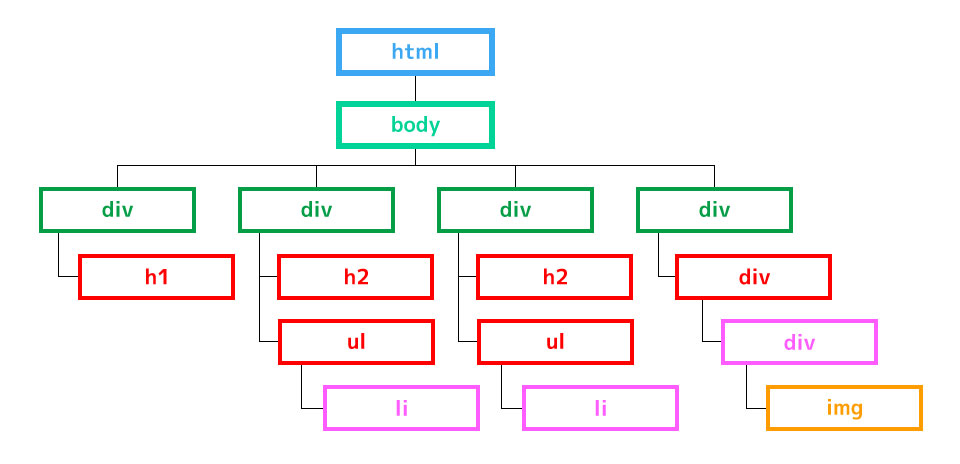
ちなみにこちらのページは公開しているので、良ければ自由に練習してみてください。

拡張機能「XPath Helper」が便利
実践には、Google Chromeの拡張機能「XPath Helper」を使っていきます。

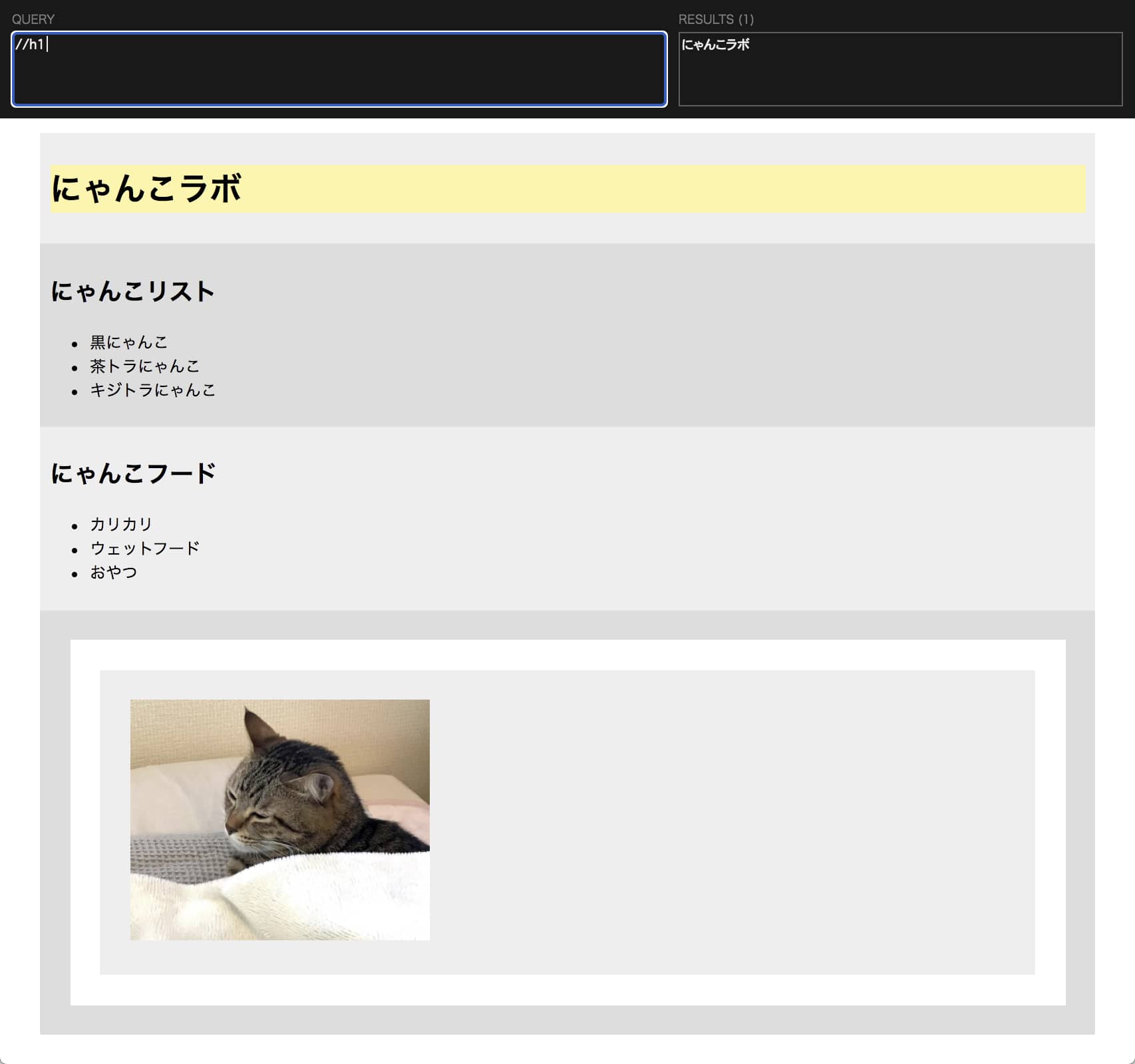
webページで「XPath Helper」を実行するとウィンドウ上部に出てくる黒帯内の「QUERY」欄にXPathを入力すると該当する箇所がリアルタイムでハイライトされるという、XPathの練習にはもってこいの拡張機能です。
1つしか存在しないタグの取得は簡単
ページに1つしか存在しないタグはめちゃくちゃ簡単に指定できます。
例えば、このページに1つしかない h1タグ を取得するには以下のように書くだけでOKです。
//h1
class名で取得した複数のタグを絞り込む
“title”というクラス名の h2タグ を取得するには以下のように書きます。
//h2[@class=”title”]
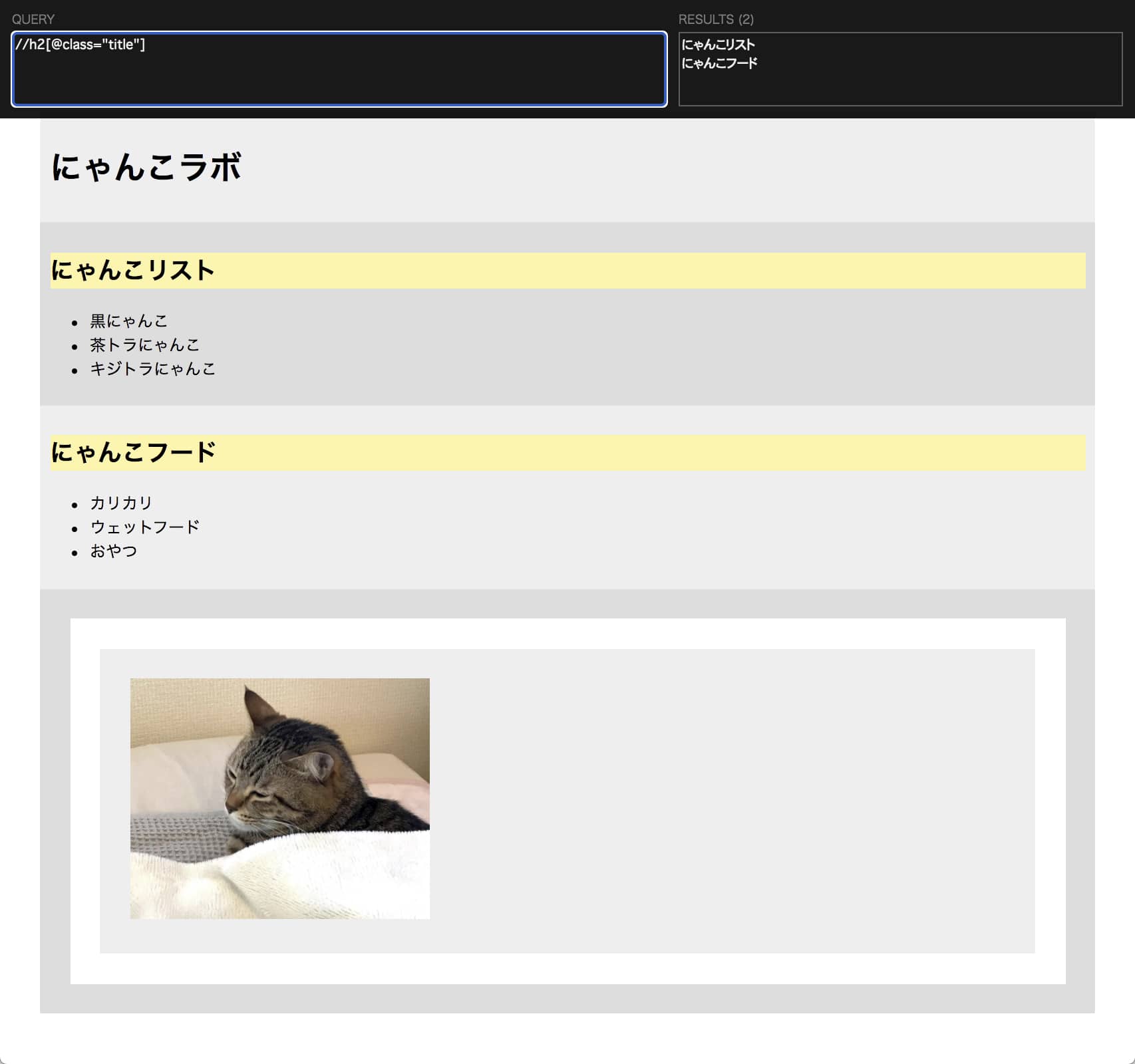
“title”というクラス名の h2タグ は2つあるので2箇所ハイライトされました。
さらに続けてもう少し試していきます。
“content”というクラス名の divタグ を取得するには以下のように書きます。
//div[@class=”content”]
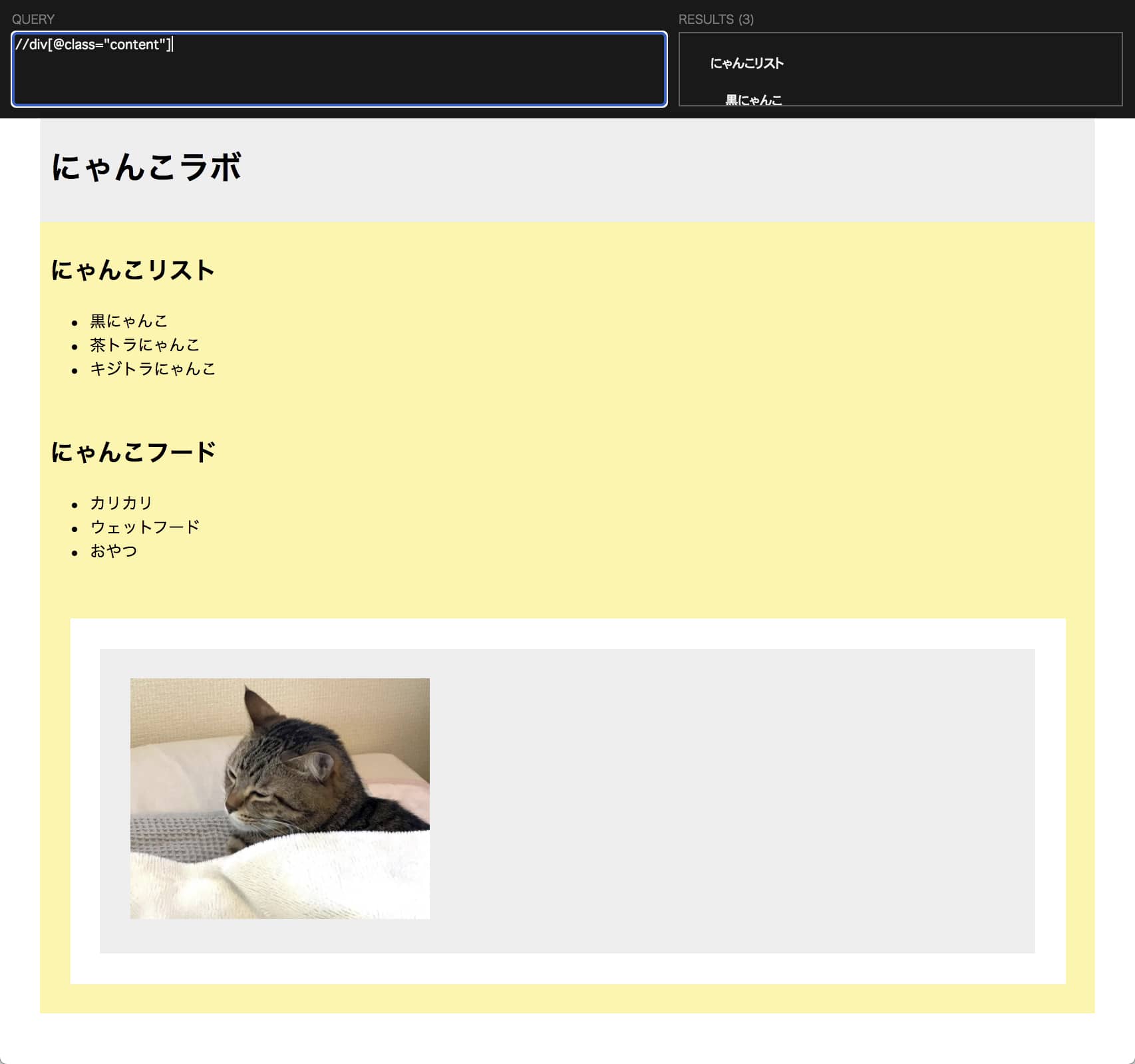
“content”というクラス名の divタグ は3つあるので3箇所ハイライトされました。
この2番目だけを取得したい場合は以下のように書きます。
//div[@class=”content”][2]
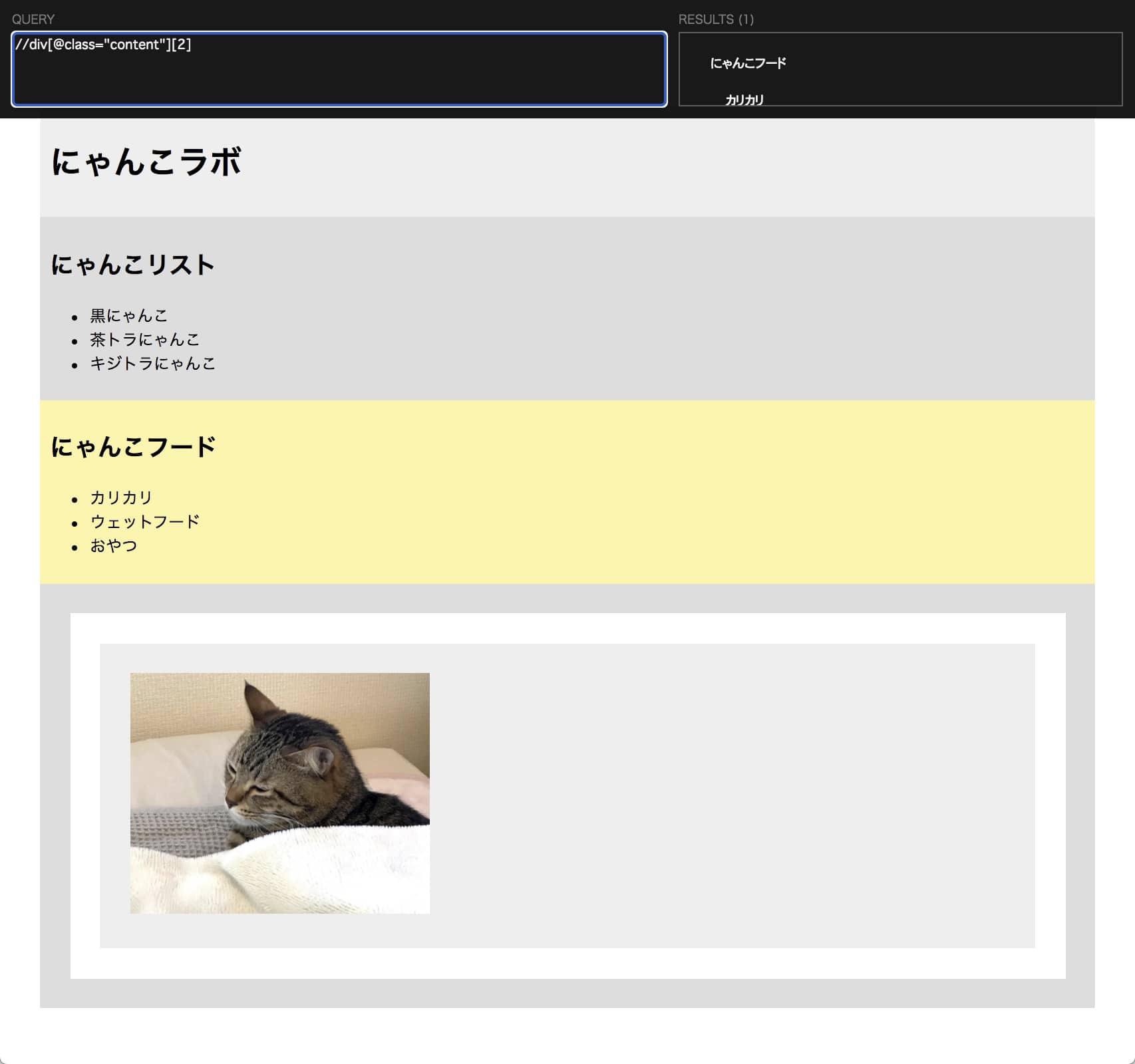
絞り込んだ要素の中の要素を取得
先程の続きで、取得した divタグ の中にある liタグ の2番目を取得するには以下のように書きます。
//div[@class=”content”][2]//li[2]
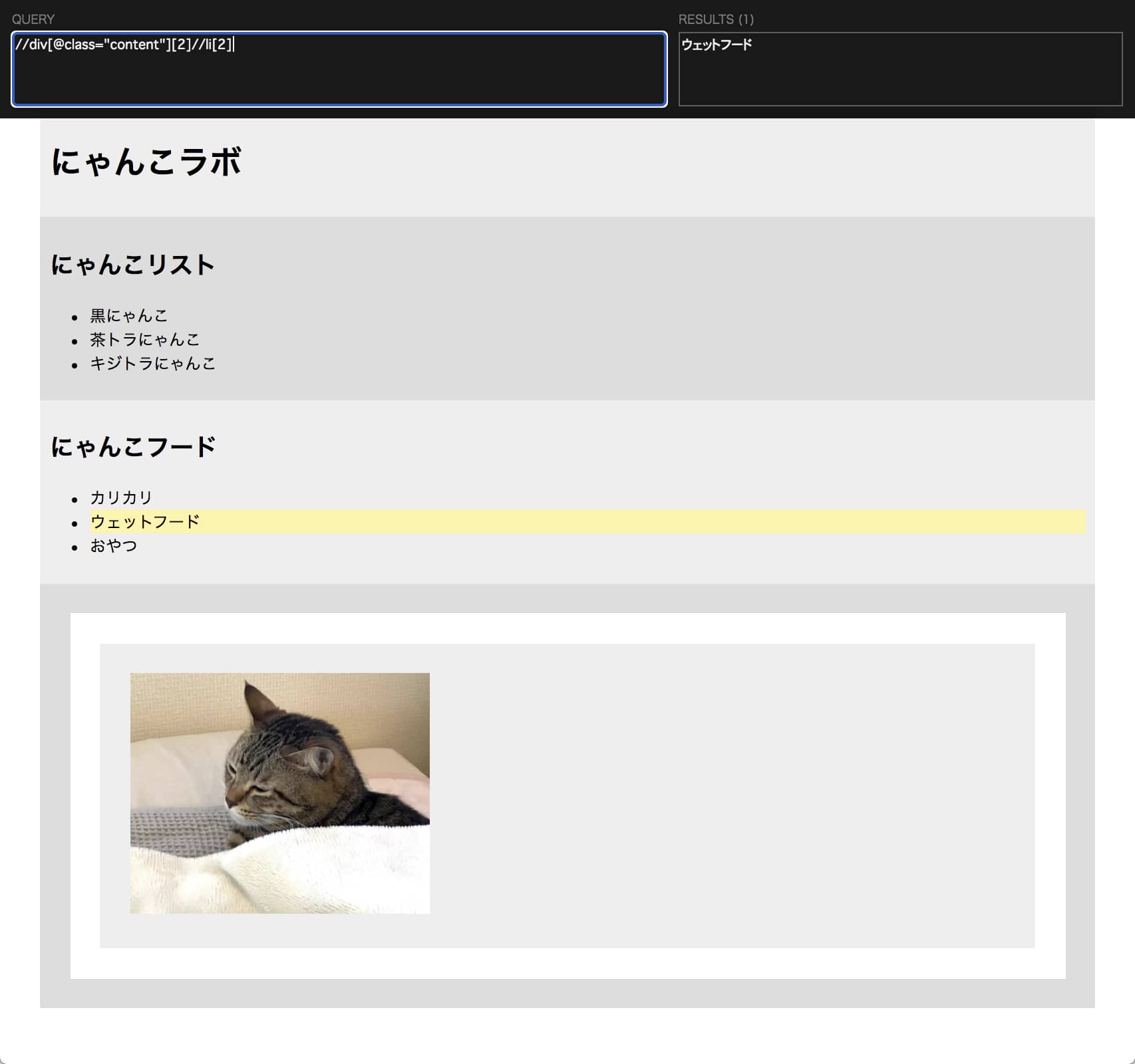
//li[2] の「//」は、liタグ の親要素 ulタグ を省略する意味です。
このように、パスの途中でも省略は可能です。
テキストは「完全一致」でしか取得できない
タグ内のテキストで取得する場合、内容が完全一致しないと取得はできません。
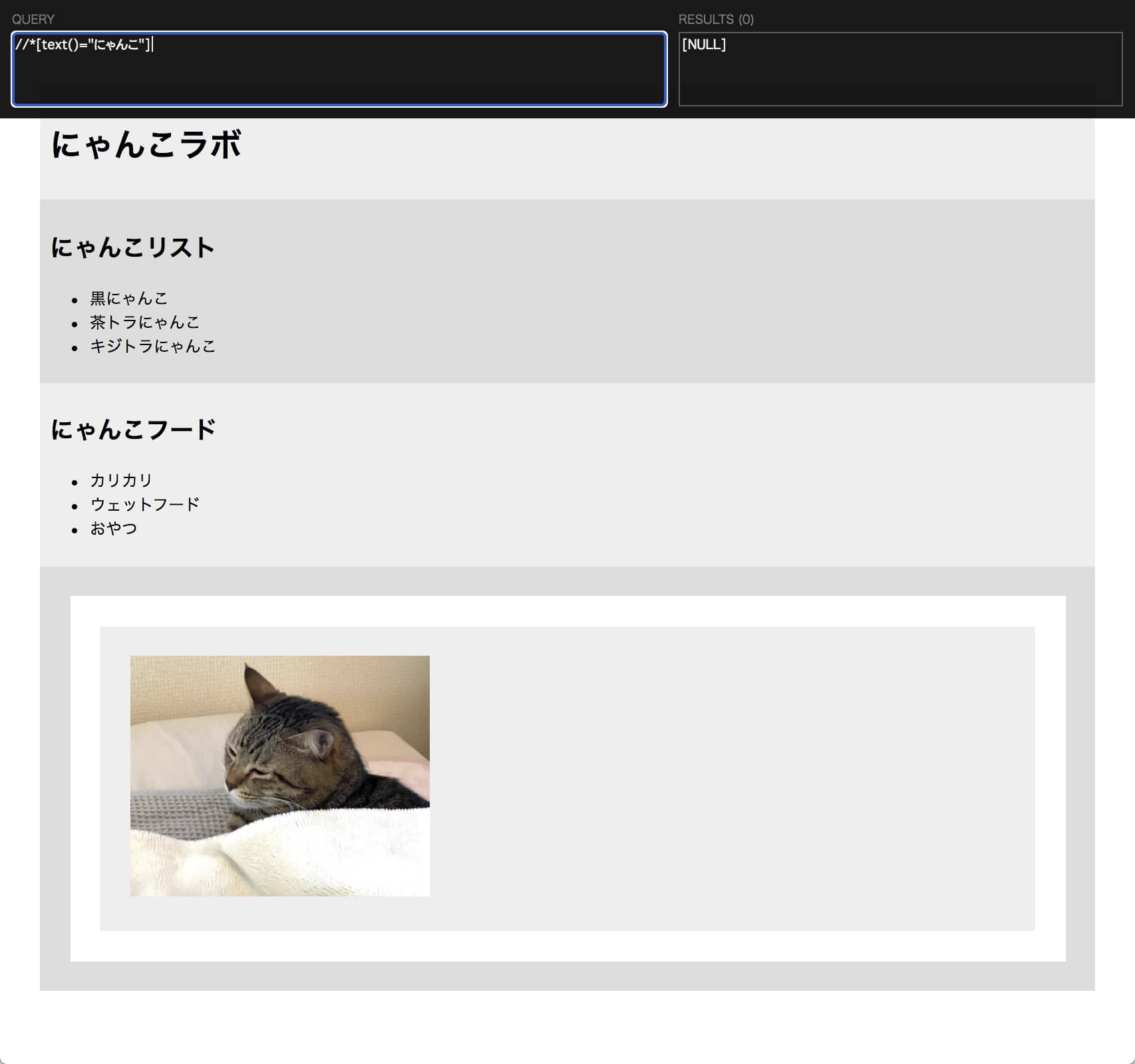
例えば、単語としては複数一致するはずの「にゃんこ」というワードを指定して書いても該当する箇所はなしとなります。
//*[text()=”にゃんこ”]
タグ名を「*」と書くと全てのタグが取得されます。
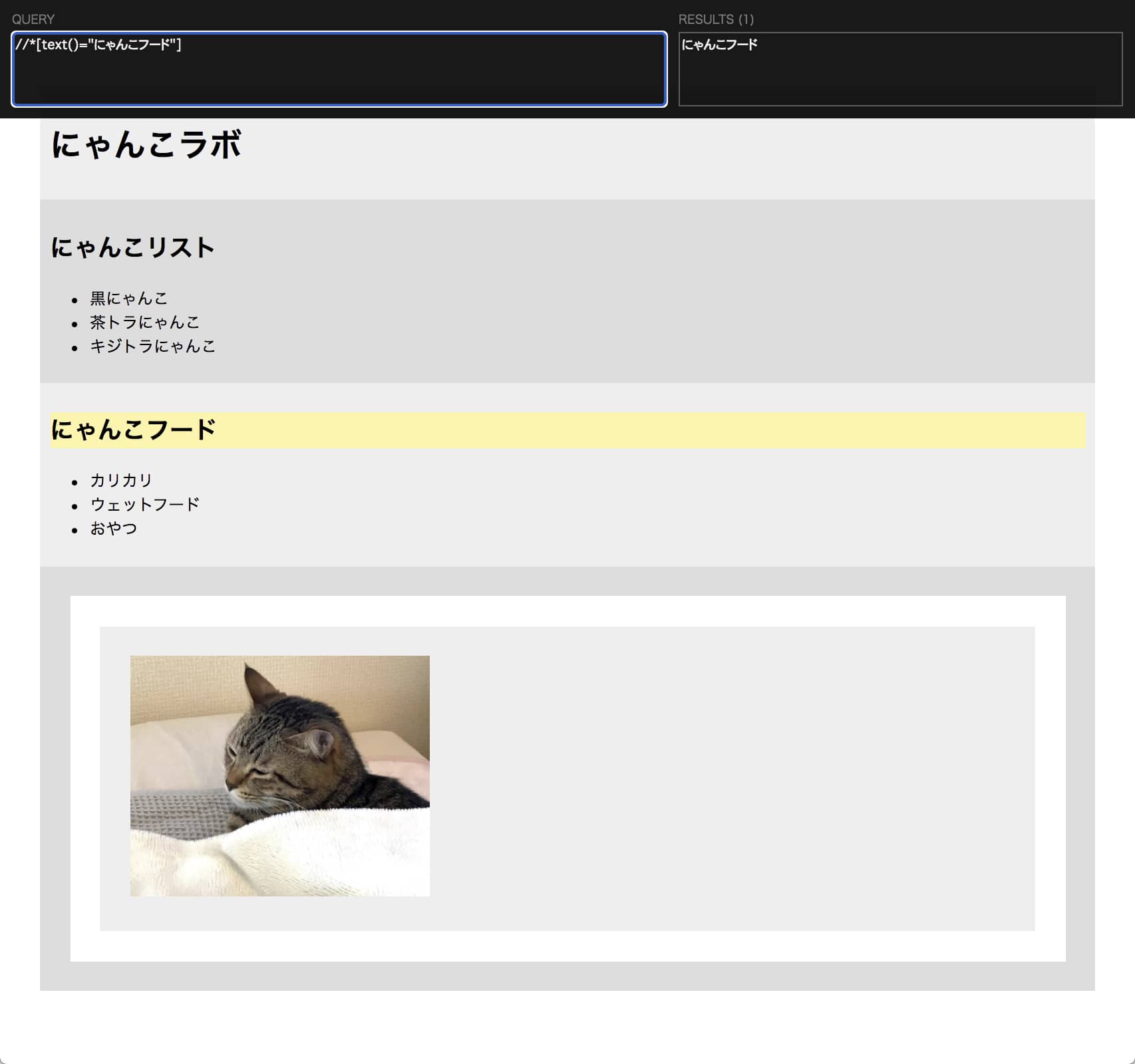
テキスト内容で取得するためには「にゃんこフード」のように内容と完全に一致させる必要があります。
//*[text()=”にゃんこフード”]
参考になったサイト様

おわりに
今回はXPath基礎レベルのご紹介でしたが、このレベルの知識でも習得しておけば十分実践で使えると思います。
本記事がどなたかの参考になれば幸いです。
今回は以上となります。
最後まで読んでいただきましてありがとうございました!
それではまた〜✧٩(ˊωˋ*)و✧
コメント